| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 트리 높이
- array
- java
- 루트노드
- 직접 주소 개방
- 자바
- 자료구조
- 배열
- Queue
- 선형 조사법
- Double Hasing
- 이진 큐
- binary queue
- Gargbae Collector
- 이차 조사법
- Double형 배열
- 큐
- Quadratic Probing
- 자식 노드
- 노드 레벨
- 부모 노드
- 조상 노드
- 향상된 for문
- Open-Addressing
- 객체 배열
- 단말노드
- ListIterator
- 해시 테이블
- Linear Probing
- singly linked list
- Today
- Total
영운's 블로그
[자료구조 Java] 힙(Heap), 이진 힙(Binary Heap) 개념 정리 + 자바로 구현하기 본문
Heap이란?
힙은 '우선순위 큐'를 구현하거나 '힙 정렬'을 하기 위해 사용하는 자료구조이다. 힙은 이진 힙(Binary Heap)이라고 부르기도 한며 둘은 동일한 개념이다. '우선순위 큐'란 특정 우선순위 기준을 가지고 만든 큐를 의미한다. 사실 기존의 큐 또한 우선순위 큐에 속한다. 기존의 큐는 삽입된 순서 기준으로 먼저 삽입된 것에 우선순위를 부여한 우선순위 큐이라고 할 수 있다.
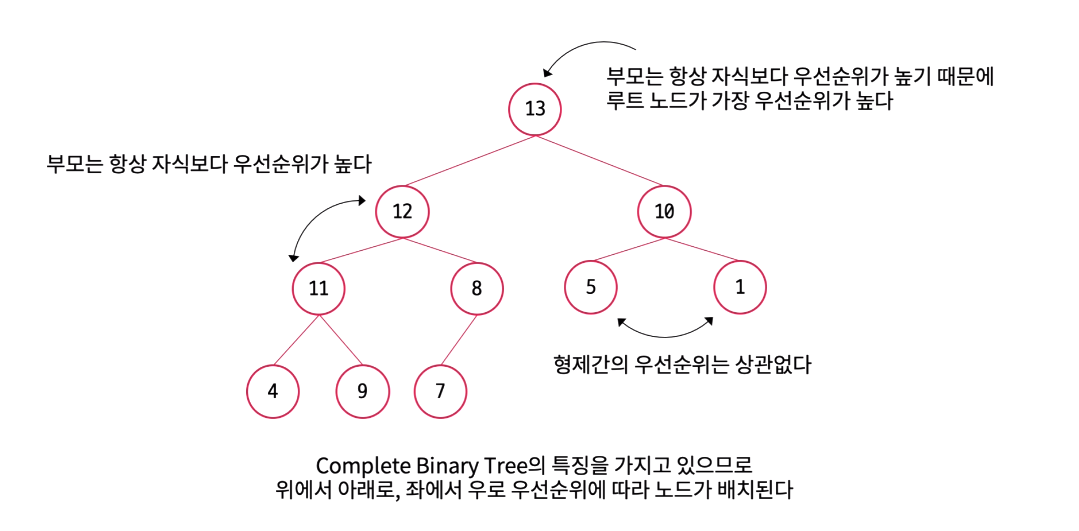
힙은 최대 힙(Max Heap)과 최소 힙(Min Heap)으로 나눌 수 있다. 최대 힙은 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 힙이다. 최소 힙은 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 힙이다. 아래부터는 최대 힙을 가정하고 힙에 대해 서술하고자 한다.
힙의 규칙은 다른 트리 자료구조들과 비교했을 때 비교적 간단하다. 힙은 큰 값이 위에 있고 작은 값들은 아래에 있는 트리로 느슨한 정렬 상태를 유지하는 트리이다. 힙은 완전 이진 트리이기에 삽입시 항상 왼쪽부터 채워지며 이진 탐색 트리와는 다르게 형제(같은 레벨의 노드)간 우선순위가 없다.
힙은 느슨한 정렬 상태를 유지하는 대신 항상 루트 노드는 가장 큰 값을 가진다. 따라서 이는 우선순위 큐를 사용하기에 아주 적합하다.
- 큰 값은 위에 있고 작은 값들은 아래에 있는 느슨한 정렬을 유지하는 트리
- 완전 이진 트리(=항상 왼쪽부터 채워지는 트리로 왼쪽 자식이 없는데 오른쪽 자식에 값이 있을 수 없다)
- 형제 노드간 우선우선순위는 없다.
- 루트 노드는 힙에서 가장 큰 값을 가진다.
- 배열을 통해 구현하기 쉽다.
힙은 완전 이진 트리이기에 중간에 데이터가 없는 빈 노드가 없어 배열로 쉽게 구현할 수 있다. 트리 형태를 배열로 구현하기 위해 다음과 같은 별도의 index 계산법을 사용한다.
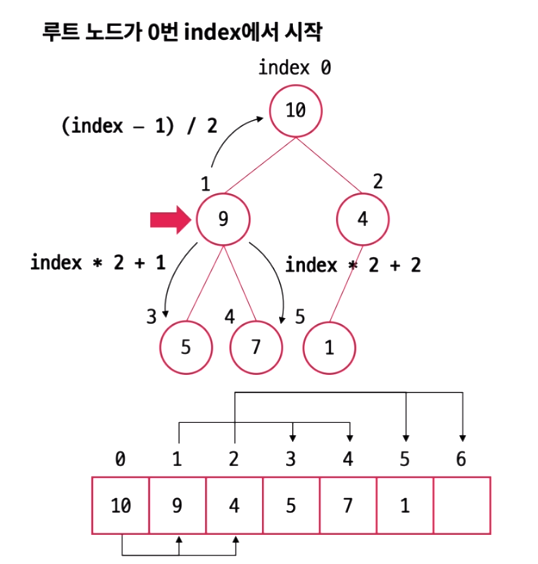
| index | |
| 루트 노드 | 0 |
| 노드 자신 | index |
| 부모 노드 | (index - 1) / 2 |
| 왼쪽 자식 노드 | index * 2 + 1 |
| 오른쪽 자식 노드 | index * 2 + 2 |
오른쪽 자식노드의 경우 부모 노드 index를 구하기 위해 (자식index -1) / 2 식을 사용하면 소수점이 나오지만 index를 int형으로 선언시 소수점은 자동으로 버려지기에 부모 노드 index를 구할 수 있다.
public class MaxHeap {
Integer[] queue;
final int ROOT_NODE_INDEX = 0;
int size = 0; // 저장된 노드의 개수
public MaxHeap(int length) {
queue = new Integer[length];
}
private int getParentIndex(int index) {
return (index - 1) / 2;
}
private int getLeftChildIndex(int index) {
return index * 2 + 1;
}
private int getRightChildIndex(int index) {
return index * 2 + 2;
}
private boolean hasLeftChild(int index) {
return size > getLeftChildIndex(index);
}
private boolean hasRightChild(int index) {
return size > getRightChildIndex(index);
}
private void swap(int index1, int index2) {
Integer tmp = queue[index1];
queue[index1] = queue[index2];
queue[index2] = tmp;
}
...
}
트리 관련 용어 간단 정리
트리라는 개념이 처음인 경우 해당 링크에서 트리에서 자주 사용되는 용어를 가볍게 살펴보는 것을 추천한다. 개념 자체가 어렵다기 보다는 용어가 생소하여 헷갈리는 것이 많기 때문이다.
Heap 삽입
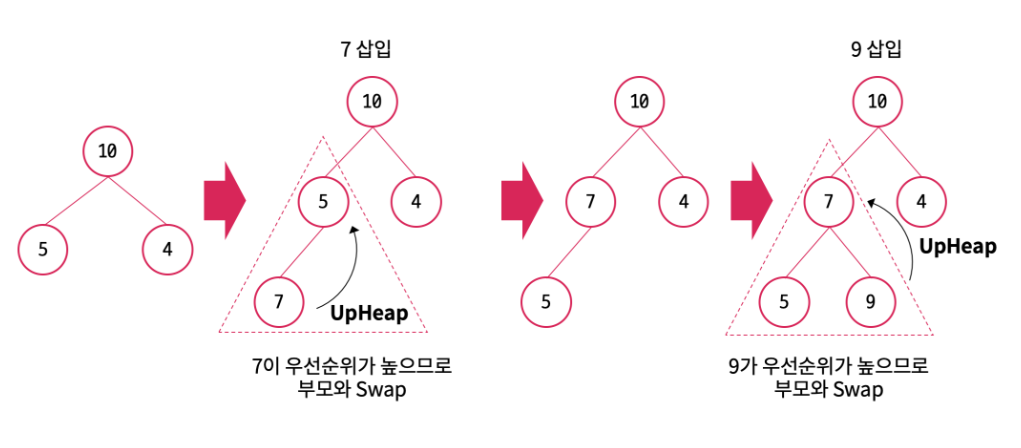
Heap의 삽입은 완전 이진 트리의 특성상 먼저 가장 왼쪽의(가장 마지막 index+1) 단말 노드에 새로운 노드를 삽입하고 해당 단말 노드에서부터 UpHeap을 진행한다. UpHeap이란 부모 노드와의 우선순위를 고려하여 부모 노드보다 우선순위가 높다면 부모 노드와 자식 노드의 위치를 바꾸는 것이다. UpHeap을 부모 노드보다 우선순위가 높지 않을 때까지 반복한다.
정리하면
- 새로운 노드를 삽입할 수 있는 레벨에서 가장 왼쪽(가장 마지막 index + 1)의 단말 노드 위치로 삽입한다.
- 부모 노드와 우선순위를 비교하여 UpHeap
- 더 이상 부모 노드의 우선순위가 높지 않을 때 까지 2.반복
public void add(Integer key) {
if (queue.length == size)
queue = Arrays.copyOf(queue, queue.length + 10);
queue[size++] = key;
upHeap(size - 1);
System.out.println(key + " 삽입 완료");
}
public void upHeap(int index) {
while (index != ROOT_NODE_INDEX && queue[index] > queue[getParentIndex(index)]) {
swap(index, getParentIndex(index));
index = getParentIndex(index);
}
}Heap 삭제
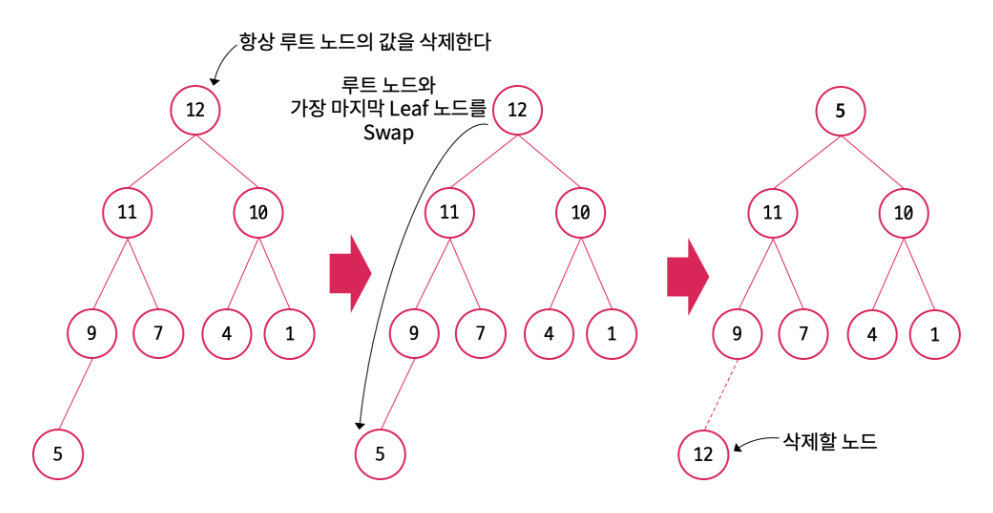

Heap의 목적은 가장 우선순위가 높은 데이터를 꺼내는 것이기에 Heap은 루트 노드만을 삭제할 수 있다. 삭제 연산시 루트 노드를 가장 마지막 index의 단말 노드와 교체하고(Key값만 교체) 부모 노드는 삭제할 노드인 해당 단말 노드와의 연결을 끊는다. 이후 루느 노드로 올라간 단말노드에 대해 DownHeap을 진행한다. DownHeap이란 자식 노드 중 우선순위가 높은 노드와 비교하여 자식 노드가 더 큰 key값을 갖는 경우 자리를 바꾸는 것을 말한다. 이를 자식 노드에 대해 계속해서 진행하여 더 이상 DownHeap이 불가할 때 까지 반복한다.
정리하면
- 루트 노드의 key값을 가장 마지막 단말 노드의 key값과 교체
- 교체된 단말 노드를 삭제
- 새롭게 루트 노드가 된 노드는 자식 노드의 우선순위가 낮을 때까지 DownHeap 반복.
public void delete() {
int leafNodeIndex = size - 1;
swap(ROOT_NODE_INDEX, leafNodeIndex);
System.out.println(queue[leafNodeIndex] + " 삭제");
queue[leafNodeIndex] = null;
size--;
DownHeap(ROOT_NODE_INDEX);
}
public void DownHeap(int index) {
int childIndex;
if(hasLeftChild(index))
childIndex = getBiggerChildIndex(index);
else
return;
while (size > index && hasLeftChild(index) && queue[index] < queue[childIndex]) {
swap(index, childIndex);
index = childIndex;
childIndex = getBiggerChildIndex(index);
}
}
private int getBiggerChildIndex(int index) {
if (hasRightChild(index))
return (queue[getLeftChildIndex(index)] >= queue[getRightChildIndex(index)]) ? getLeftChildIndex(index) : getRightChildIndex(index);
else if (hasLeftChild(index))
return getLeftChildIndex(index);
else//자식 노드가 없는 단말 노드인 경우
return -1;
}
코드 실행
public class Main {
public static void main(String[] args) {
MaxHeap heap = new MaxHeap(50);
heap.add(12);
heap.add(11);
heap.add(10);
heap.add(9);
heap.add(7);
heap.add(4);
heap.add(1);
heap.add(5);
heap.printHeap();
heap.peek();
heap.delete();
heap.peek();
heap.printHeap();
}
}- 실행 결과 -

전체 코드
https://github.com/you88311/data-structure
GitHub - you88311/data-structure
Contribute to you88311/data-structure development by creating an account on GitHub.
github.com
참고
https://www.codelatte.io/courses/java_data_structure
자바 자료구조 강의 - 코드라떼
컴퓨터 공학 2단계 자바 자료구조 강의입니다. 대부분의 프로그래밍하는 과정은 데이터를 다루는 일입니다. 데이터를 어떻게 잘 저장하고 관리할 수 있는지 자료구조에 대해 배웁니다. 자료구
www.codelatte.io
C언어로 쉽게 풀어쓴 자료구조 - 천인국, 공용해, 하상호 지음
'자료구조' 카테고리의 다른 글
| [자료구조 Java] 해시 테이블 (2) - 체이닝(Chaining), 선형 조사법(Linear Probing), 이차 조사법(Quadratic Probing), 이중 해싱법(Double Hasing) (0) | 2022.07.16 |
|---|---|
| [자료구조 Java] 해시 테이블 (1) - 해시 테이블 및 해시 충돌(Hash Collision) (0) | 2022.07.16 |
| [자료구조] 트리(Tree) 관련 용어 간단 정리 (0) | 2022.07.09 |
| [자료구조 Java] 이진 탐색 트리(Binary Search Tree) 개념 정리 + 자바로 구현하기 (0) | 2022.07.09 |
| [자료구조 Java] 큐(Queue) 개념 정리 + 자바로 구현하기 (0) | 2022.07.07 |



